문자열 탐색에는 regex(정규식)도 자주 쓰이는 편이지만, 웹페이지를 분석할 때는 그렇지 않습니다.
대부분 BeautifulSoup를 사용하니까요.
그런데 RSS 피드나 XML 문서의 경우에는 구조가 단순하기 때문에 regex를 사용해도 괜찮지 않을까 하는 생각이 들었습니다.
이걸 파싱 속도라고 하는게 맞나 고민되지만, 이렇게 표현하는게 좀 더 와닿을 것 같아서 파싱이라는 단어를 사용해보았습니다.
혹시 regex의 속도가 느려서 사용하지 않는건가 하는 생각이 떠올랐는데, 그렇다면 얼마나 속도가 차이나는지 확인해보기로 했습니다.
먼저 테스트를 위해 RSS 피드를 읽어보겠습니다.
다음은 네이버 블로그팀(https://blog.naver.com/blogpeople)에서 운영하는 네이버 블로그의 RSS를 요청하고, 각각 bs4와 regex를 이용해 데이터를 변환하는 시간을 측정하는 코드입니다.
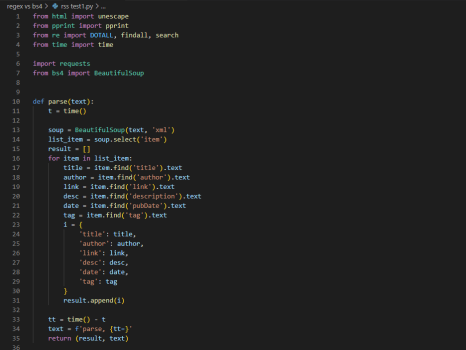
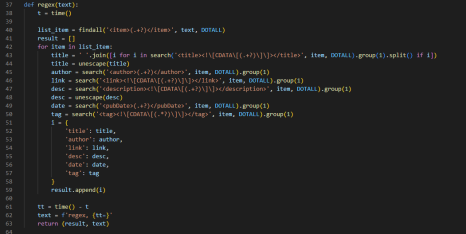
결과는 예상과 달랐습니다.
bs4를 이용했을 때는 0.027초의 시간이 소요되었고, regex를 사용했을 때는 0.005초가 소요되었습니다.
regex가 훨씬 빠르네요.

네이버 블로그의 RSS 피드에서 제공하는 게시물이 50개라 텍스트 양이 적어서 그럴 수도 있다고 생각했습니다.
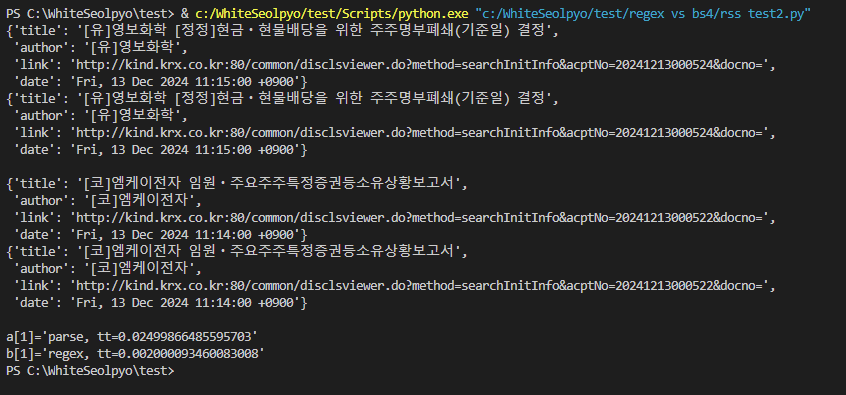
그래서 RSS피드에서 좀 더 많은 게시물을 제공해주는게 없을까 찾아보던 중에 KIND 기업공시 채널(https://kind.krx.co.kr/disclosure/todaydisclosure.do)에서 최대 100개의 피드를 제공해주는 것을 알게 되었습니다.
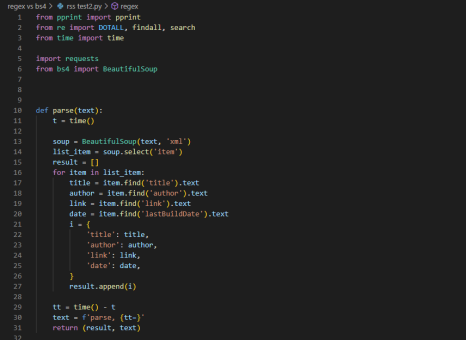
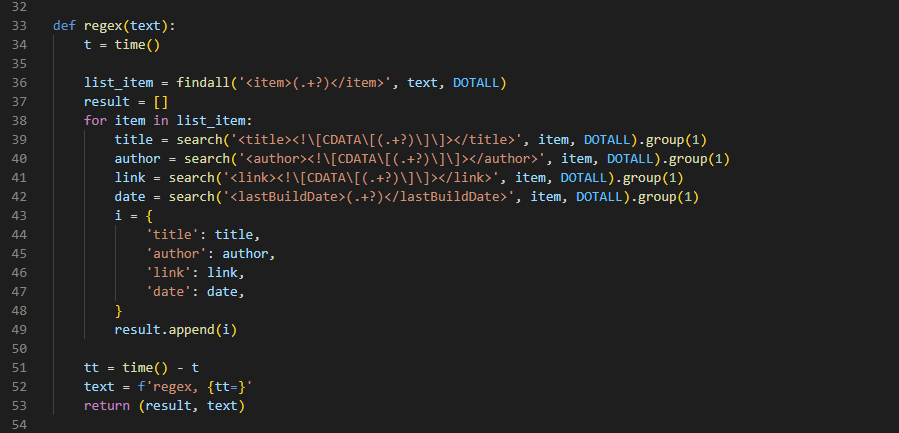
결과는 이전과 같았습니다.
bs4를 이용했을 때는 0.025초가, regex를 이용했을 때는 0.002초가 소요되었습니다.
xml 문서는 regex가 확실하게 빠른 것을 알게 되었으니, 다음은 html 문서를 변환해볼 차례입니다.
간단하게 네이버 뉴스 검색결과 페이지를 변환해보는 코드를 작성해봤습니다.
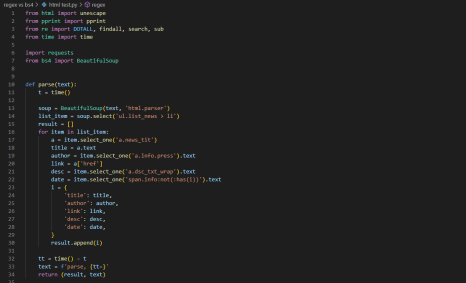
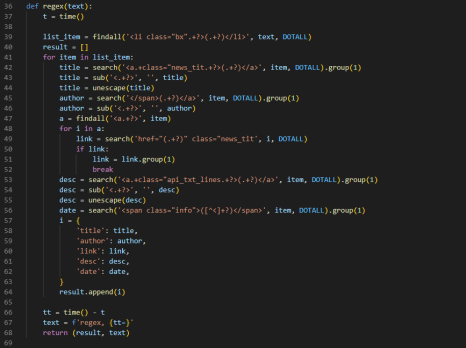
html 문서 역시 regex를 사용하는게 더 빨랐지만... 한 가지 알게 된 사실이 있었습니다.
regex 문법을 작성하는데 많은 시간이 소모된다는 것입니다.
그마저도 regex를 사용해서 어떻게 구현을 하긴 했는데, regex를 잘하지 못해서 for loop문을 이용할 수 밖에 없었습니다.
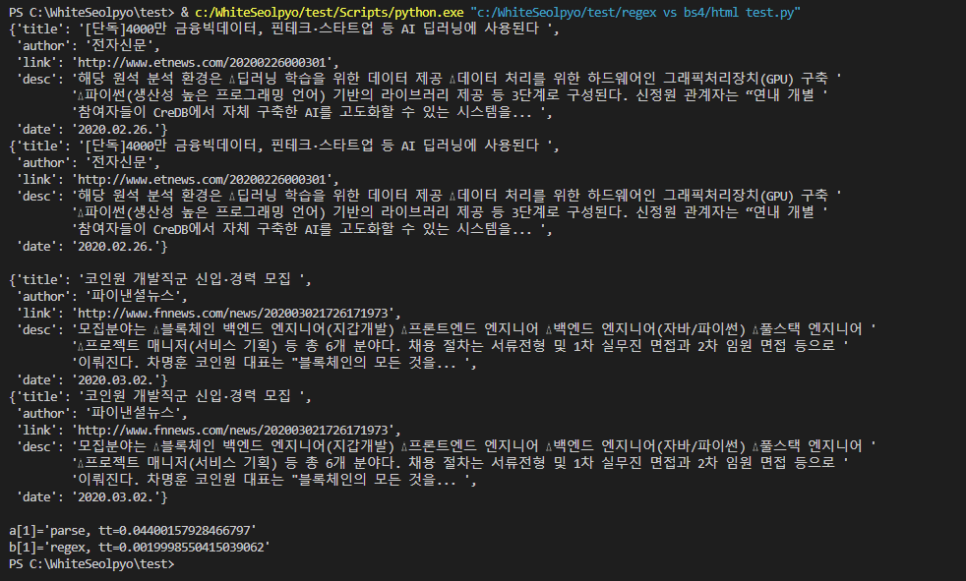
bs4를 사용한 코드는 regex 코드와 다르게 루프문이 없음에도 0.044초라는 시간이 소요되었고, 루프문을 사용한 regex 코드는 0.002초의 시간이 소요되었습니다.
간단 요약
- 웹페이지를 크롤링한 결과를 변환할 때 bs4의 BeautifulSoup를 많이 사용하지만, 코드 작동 시간은 regex를 사용하는게 더 빠르다.
- 같은 이름의 태그가 여러개 존재하는 경우, regex 문법을 사용하는 코드를 작성하기 어려워진다. 즉, 작업 시간이 길어진다.
- 작업할 시간이 많거나, 문자열의 구조가 단순하면 regex를 사용하는 것도 좋은 선택일 수 있지만, bs4를 사용하더라도 짧은 시간이 소요되므로 유의미한 차이는 없을 수 있다.
테스트 코드 깃헙 링크 : https://github.com/white-seolpyo/regex-vs-bs4